


Meeting machine learning challenges head-on in our quest to automate online ad filtering
Technology advances at the speed of light. Continuous experimentation is needed to keep our tech competitive and innovative. Our current foray into applying machine learning to our ad-filtering core will give our partners cutting edge options to enhance their own products. These advances will allow them to increase their user satisfaction and save on internal resources and time.
Experimenting isn’t without its challenges. Here at eyeo, we embrace failure as long as we learn from it. The following is Part 3 of a series detailing our journey to automate online ad filtering using a machine learning project, Project Moonshot, and discusses the obstacles that happen when you innovate. (You can also check out Part 1: Scaling ad filtering and Part 2: Ideas take flight on the eyeo blog.)
Some challenges we overcame and helped us optimize the process, others led us to change course. Learning from failing is the only way to ultimately innovate.
"A person who never made a mistake, never tried anything new." Albert Einstein
On this journey into the unknown, we’ve faced challenges with data collection, creating better, faster models to get ahead of the continual cat-and-mouse game of circumvention, and bridging the gap between tools and technology to optimize our processes.
Data collection
Regardless of the model type, it's a challenge to figure out what kind of data needs to be collected. So first we assessed which features will allow the algorithm to pick up on the right clues. What’s important? Content size? Placement? Text size? Which features distinguish an ad from content? Not knowing beforehand makes feature prioritization difficult. So there’s some experimenting involved.
One early avenue that was explored but discarded was Perceptual Ad Detection which uses visual content to detect ads rather than the metadata (website layout, textual elements). We took screenshots of the page and used computer vision techniques like YOLO and SIFT-based feature extraction to visually identify the ads based on image features like size or if the “sponsored” or “adchoices” logos were present, etc.
But, very soon we became aware of a few problems here
(1) such a system was easy to dodge (and a lot of research is being done where adversarial machine learning is targeting Perceptual Ad Detection)
(2) the computer vision models were huge and became heavy on browser resources for any real-time processing
(3) computer vision might be a better fit for solving problems like autonomous driving, but the ad data is very unstructured because the same visuals may be part of organic or ad content and
(4) finally, data collection and processing became a big data problem itself.
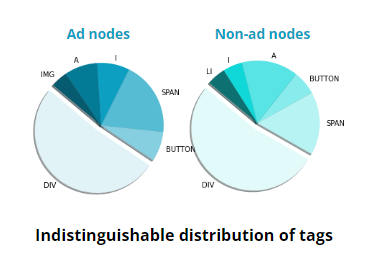
Based on these downsides of visual ad detection, we moved to using the raw HTML of the page. Using HTML was much more robust. Not only were the standalone tags useful, but also the overall tree structure of the page was helpful and increased our model performance in the later steps.
Machine learning models need data to learn but it can’t just be any data. We collected a lot of raw data but it has to contain enough variety so that it can be effective when processed. This is crucial. The variety can balance the data so the models don’t come to incorrect conclusions by over- or under- fitting.
By default, ad-data distribution on pages is very unbalanced: 95% of the data is non-ad and only 5% is ad. Also, the distribution of HTML tags between ads and non-ads is similar. To find a good balance, we hand-picked websites to comb for variegated data. We used data augmentation to generate additional data to fill this gap. Then we sorted out the unwanted (duplicate and irrelevant) data during training.
We tried a variety of models to improve the balance of the data. To date, we’ve had the most success with a hybrid of the graph– and tree-based machine learning models. However, we feel we can improve upon this and are looking for ways to further diversify our data collection.
Cat and mouse
Our ad-filtering technology uses ad blockers to stop intrusive, noncompliant ads while only allowing ads that meet the standard of Acceptable Ads. In this way we filter the ads on a website. Circumvention of ad blockers and then blocking that circumvention is a continual cat-and-mouse game, making it difficult to collect data, and it requires constant re-training of models.
The challenge is creating faster and better models to keep up with the evasive countermeasures so we can collect accurate data for the models. In our experiments, we realized that different models have different conversion implementations and some were extremely slow, and therefore not going to be effective in this game.
The gap between the tools and the technology
Our machine learning research and development is carried out in python-based tools. However, for deployment in browsers/extensions we need Javascript which doesn’t have as mature an ecosystem of machine learning libraries as Python. We need ways to fill this gap between tools and tech.
Since the model needs the same data input during the inference phase as the one we feed it with during the training phase on the server, we exported the existing feature extraction and inference pipeline from Python to JavaScript.
As an alternative, we also considered using WebAssembly for this task. WebAssembly was faster while consuming less RAM, but it came with its own set of challenges when deploying into production. One of these challenges was the inflated size of the WebAssembly module that led to increased size of extension. Another one was that it would require a more complicated integration with the rest of the Adblock Plus. These challenges made it so that WebAssembly wasn’t a viable option for us, and the Javascript data conversion module proved to be fast-enough for the time being.
Conclusion
Failure is an integral part of inventing. Oftentimes, a challenge or a misstep allows us to start over more informed and more intelligently. Whereas some companies may not want to admit they’ve ever failed, we think it’s important to show that on our journey to create something completely new and cutting edge, we’ve had to fail a few times to make it great.
Just like the models we’re training, we’re taking the data from our successes and failures in Project Moonshot to learn how to optimize our ad-filtering technology. We are continuously experimenting with data, different machine learning models and combinations for better results. Stay tuned as we continue to push forward into new territory.


